 Pythonによるデータ分析
Pythonによるデータ分析
Pythonによるデータ分析
Pythonによるデータ分析
データの順番に意味があっても、それは メタ知識 になっていて、データには書いていないことがあります。
そんな時は、その意味をデータに書き足すと、分析できることがかなり増えます。 データの切り貼り ができることも増えます。
この作業は、ExcelではIF関数を使ったりして、データに直接的に行うので、そんなに困らないです。 しかし、作業の効率化のためにPythonを使う場合は、「どうやるのだろう・・・」となって来ます。 (筆者がそうでしたので)
下記は、Pythonを使う時のメモです。 Pythonによる準周期データの分析 では、このページの内容が不可欠になっています。
以下の、コードは、「df」という形でフレーム形式のデータが入力されている状態がスタートになっています。 データがcsvファイルの場合は、入力方法は下記になります。
import pandas as pd # パッケージの読み込み
df= pd.read_csv("Data.csv" , engine='python')# データを読み込む
日本語が含まれていないなら、「engine='python'」はなくても良いです。
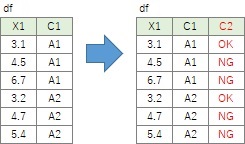
この例は、X1が4を境にして、「OK」と「NG」の違いが決まっているケースです。
製造業では、製品の合否判定のデータでこのような場合があります。
Excelなら、IF関数を使う処理です。
df['C2']=df.X1.apply(lambda x:'OK' if x <4 else 'NG')
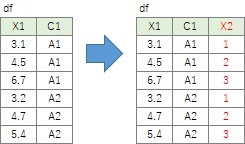
同じカテゴリに連番を付けます。
カテゴリの中の順番を表す変数ができるので、
経時解析
ができるようになります。
Excelなら、IF関数を使うことになるのですが、前の行の値を参照するので、少しややこしくなります。
なお、この例では、元のデータが時間の順番になっていて、また、 同じカテゴリが時間が経ってからまた出てこないことを前提にしています。 製造業ではロット単位で製品を作るので、こういうデータがあります。 この前提が当てはまらない場合は、ケースバイケースの対応が必要です。
df['X2']=df.groupby('C1').cumcount()+1
最後の「+1」がないと、0からの連番になります。
グループが2つの変数の組み合わせの場合は、下記になります。
df['X2']=df.groupby(['C1','C2']).cumcount()+1
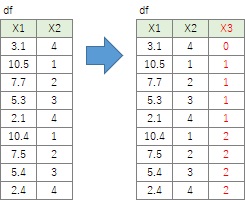
連番の繰り返しが、周期的に起きていることの周期を表していることがあります。
製造業では、ロットやバッチがこの周期になっています。 ロットやバッチの違いを分析したい時には、周期ごとに値が変わっている変数があれば欲しいので追加します。
df['X3'] = (df['X2'] == 1).cumsum() # 1が来る毎に、累積する。この場合は累積する値が1なので、1ずつ増える。
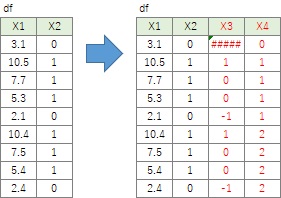
0と1の並び方の繰り返しが、周期的に起きていることの周期を表していることがあります。
機械のデータだと、0が停止している時で、1が動いている時を表していたりします。
差分( 速度データ )を作ると、連番のメタ知識からグループ変数を作成する方法が使えるようになります。
df['X3']=df.X2.diff() # 差分のデータを作る
df['X4'] = (df['X3'] == 1).cumsum() # 差分のデータが「1」の時に累積する
このデータができると、グループ変数のX4を参照することで、グループ毎に連番を付けることもできます。
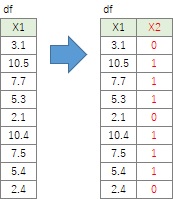
都合の良い0と1のデータがなくても、周期によって高低を繰り返しているデータがあれば、
それを0-1データに変換することができます。
工場のデータだと、電流値、流量、温度といったデータを見ると、 機械が動いている時と止まっている時で、値が大きく違っていることがありますので、 この性質を使います。
方法は、上記の条件付けと同じです。 ここでは、4を判定値にしています。
df['X2']=df.X1.apply(lambda x:0 if x <4 else 1)
https://teratail.com/questions/169558
上記の、連番からのグルーピングは、このページを参照させていただきました。
